記錄學習內容。
主要是看網路上的文章和影片,做些紀錄。
內容可能有錯誤。
主要是把這邊當作自己寫筆記的地方。
想要來用文字辨識,先想辦法用Tesseract套件:
Text Detection with OpenCV in Python | OCR using Tesseract (2020)
先來下載Tesseract:
https://tesseract-ocr.github.io/tessdoc/Downloads.html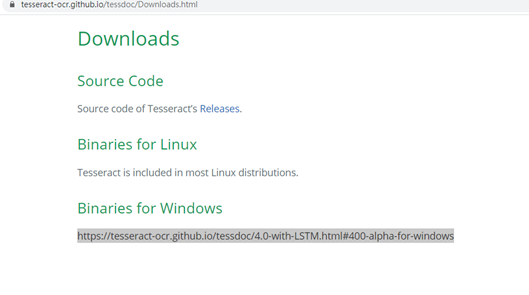
到這邊:
https://tesseract-ocr.github.io/tessdoc/4.0-with-LSTM.html#400-alpha-for-windows
下載Windows Installer made with MinGW-w64
下載後的目錄:
C:\Program Files (x86)\Tesseract-OCR
在jupyter 查看python版本:
import sys
sys.version
windows cmd 查看python版本:
python –version
安裝兩個套件
1
cv2 :
pip install opencv-python
2
pytesseract
pip install pytesseract
圖片路徑有中文會有錯誤 ,先換成英文路徑測試。
TesseractError: (1, 'Error opening data file \\Program Files (x86)\\Tesseract-OCR\\eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'eng\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
TESSDATA_PREFIX environment variable is set to your "tessdata" directory
所以來找TESSDATA_PREFIX 環境變數 是什麼 ?
就是新增這個環境變數:
TESSDATA_PREFIX C:\Program Files (x86)\Tesseract-OCR\tessdata
參考:
使用pytesseract圖像處理之中文識別(二)
之後關掉cmd ,再開一次jupyter notebook ,就可以跑了
接著來看怎麼辨識 中文 :
Day26-聽過 OCR 嗎? 實作看看吧 -- pytesseract
下載檔案:
https://github.com/tesseract-ocr/tessdata_best
繁體: chi_tra.traineddata
簡體: chi_sim.traineddata
放到C:\Program Files (x86)\Tesseract-OCR\tessdata
再跑print(pytesseract.image_to_string(img, lang="chi_tra")) 時 ,遇到錯誤:
TesseractError: (3221225477, '')
解決方法:
環境變數PATH 新增:
C:\Program Files (x86)\Tesseract-OCR\tessdata
C:\Program Files (x86)\Tesseract-OCR
之後關掉cmd ,再開一次jupyter notebook ,結果還是TesseractError
,不知道為何 ,接著試了其他語言也不行,所以不是中文的問題。
找到這篇文章:
pytesseract.pytesseract.TesseractError: (3221225477, '')
然後看了一下github的說明 ,作者認為5.0.0-alpha 比 Tesseract 4.1.0 好:
We don't provide an installer for Tesseract 4.1.0 because we think that the latest version 5.0.0-alpha is better for most Windows users in many aspects (functionality, speed, stability).
上面一開始載的,應該是4版本,因為檔案都是3年前的,而且寫Windows 4.x
。然後各個版本可以在這邊下載:
https://digi.bib.uni-mannheim.de/tesseract/
那就重新安裝 最新的這個版本 試試看:
tesseract-ocr-w64-setup-v5.0.0-alpha.20200328.exe
因為是64版本,所以路徑改成這樣:
C:\Program Files\Tesseract-OCR
再去環境變數 改成Program Files ,程式裡的路徑也改成Program Files
,然後語言包在記得放。
執行程式後 ,終於看到中文了!

